
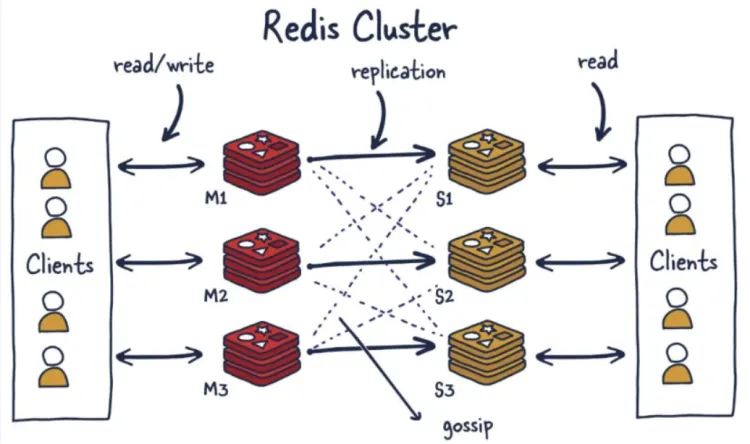
Redis集群
什么是集群
定义:
由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展,每个复制集只负责存储整个数据集的一部分。提供在多个Redis节点间共享数据的程序集。
作用:
- 集群支持多个master,每个master又可以挂载多个slave
- 由于cluster自带哨兵的故障转移功能,因此无需再去使用哨兵功能
- 客户端与Reids的节点连接,不再需要连接集群的所有节点,只需连接集群中的任意一个可用节点即可
- 槽位slot负责分配到各个物理节点,由对应的集群来负责维护,节点,插槽和数据之间的关系
槽位
什么是槽位
Redis集群没有使用一致性hash,而是引入了哈希槽概念。
Redis集群由16384个哈希槽(理解为整个小区有16384个房间),每个key通过CRC16算法,然后对16384进行取模,后得到槽位号(可以理解为门牌号),集群的每个节点负责一部分哈希槽(每个单元对应一部分门牌号),举例:
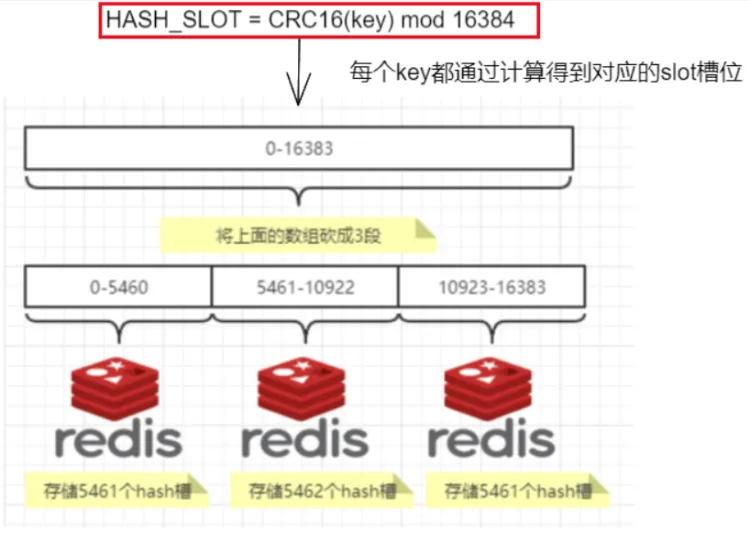
槽位的映射
①哈希取余分区法
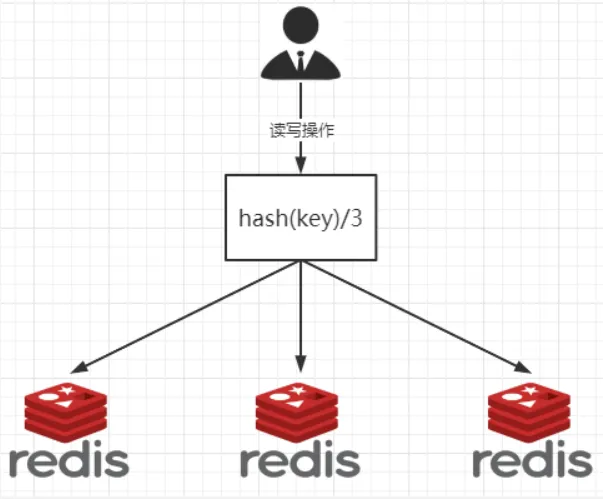
<font style="color:rgb(0, 0, 0);">2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:</font>
<font style="color:rgb(0, 0, 0);">hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。</font>
<font style="color:#0000ff;">优点:</font>
<font style="color:rgb(0, 0, 0);">简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。</font>
<font style="color:#0000ff;">缺点:</font>
<font style="color:rgb(0, 0, 0);">原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。</font>
②一致性哈希算法分区
背景:
1997年由麻省理工提出,为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母的数量就变了,自然取就不一样了。
作用:
提出一致性hash解决方案,目的是当服务器数量发生变动时,尽量减少影响客户端到服务器的映射关系。
三大步骤:
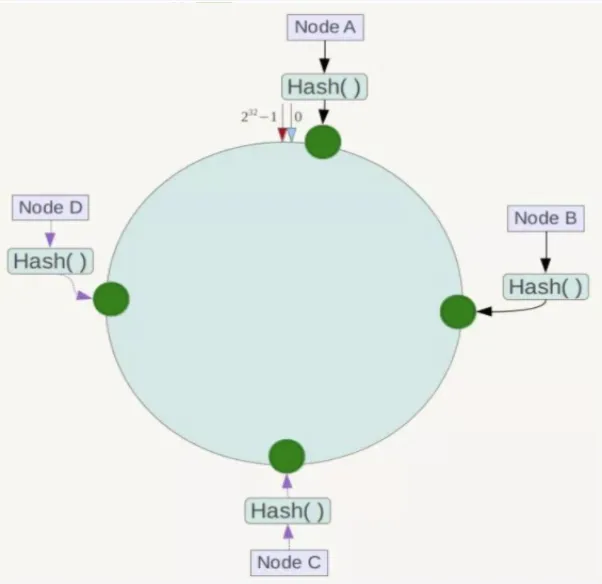
第一步:算法构建<font style="color:rgb(0, 0, 255);background-color:rgb(243, 244, 250);">一致性哈希环</font>
<font style="color:rgb(0, 0, 0);background-color:rgb(243, 244, 250);">一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。</font>
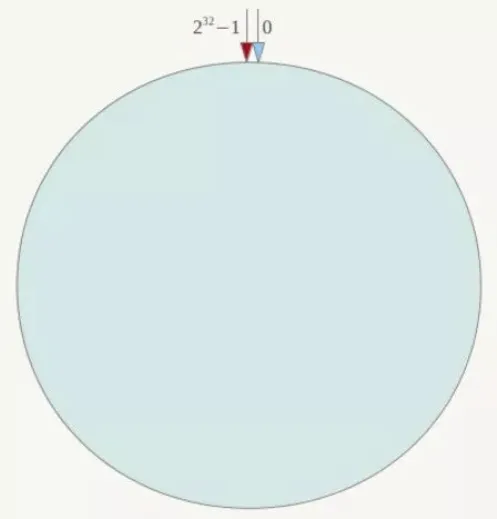
第二部:Redis服务器IP**<font style="color:rgb(0, 0, 255);background-color:rgb(243, 244, 250);">节点映射</font>**
<font style="color:rgb(0, 0, 0);background-color:rgb(243, 244, 250);">将集群中各个IP节点映射到环上的某一个位置。</font>
<font style="color:rgb(0, 0, 0);background-color:rgb(243, 244, 250);">将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的</font><font style="color:#ff0000;background-color:rgb(243, 244, 250);">哈希函数</font><font style="color:rgb(0, 0, 0);background-color:rgb(243, 244, 250);">计算(hash(ip)),使用IP地址哈希后在环空间的位置如下: </font>
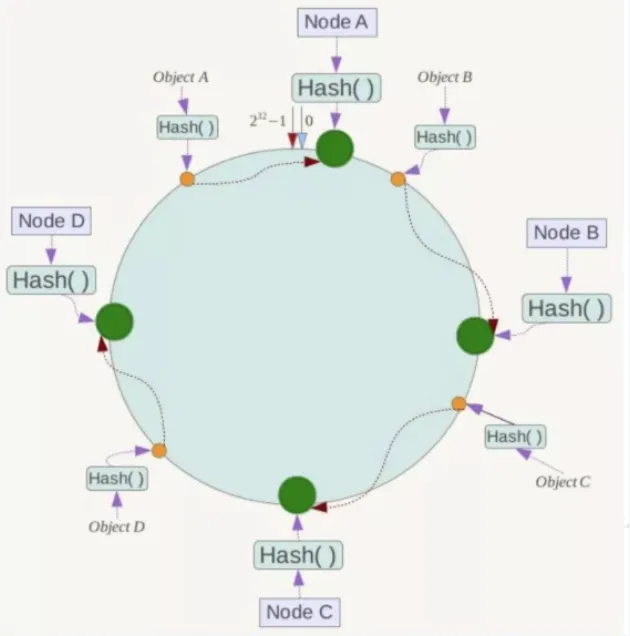
第三步:key落到服务器上的落健规则
<font style="color:rgb(0, 0, 0);background-color:rgb(243, 244, 250);">当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,</font><font style="color:#ff0000;background-color:rgb(243, 244, 250);">从此位置沿环顺时针“行走”</font><font style="color:rgb(0, 0, 0);background-color:rgb(243, 244, 250);">,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。</font>
<font style="color:rgb(0, 0, 0);background-color:rgb(243, 244, 250);">如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。</font>
优点:
- 容错性
- 扩展性
缺点:
- 容易数据倾斜
③:哈希槽分区
<font style="color:#0000ff;">1 为什么出现</font>
为了解决一致性哈希算法的数据倾斜问题
<font style="color:rgb(0, 0, 0);">哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。</font>
<font style="color:rgb(0, 0, 255);">2 能干什么</font>
<font style="color:rgb(0, 0, 0);">解决均匀分配的问题,</font><font style="color:#ff0000;">在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系</font><font style="color:rgb(0, 0, 0);">,现在就相当于节点上放的是槽,槽里放的是数据。</font>
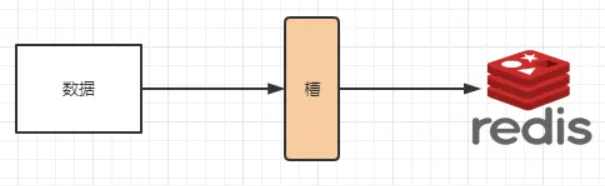
<font style="color:rgb(0, 0, 0);">槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配</font>
<font style="color:#0000ff;">3 多少个hash槽</font>
<font style="color:rgb(0, 0, 0);">一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。</font>
<font style="color:rgb(0, 0, 0);">集群会记录节点和槽的对应关系,解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取模,余数是几key就落入对应的槽里。HASH_SLOT = CRC16(key) mod 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。</font>
分片
使用Redis集群时,我们会将存储的数据分散到多台Redis机器上,这成为分片。简而言之,及群众的每个实例都被认为是整个数据的一个分片。
如何找到给定key的分片:
为了找到给定key的分片,我们对key通过CRC16(key)算法,完后对总分片数进行取模,然后,<font style="color:#DF2A3F;">使用确定性哈希函数</font>,这一意味着给定的key,将**<font style="color:#DF2A3F;">多次始终映射到同一分片</font>**,我们可以推断将来读取数据的特定key的位置。