
InnoDB中索引的推演
看一个精确匹配的例子:select * from table1 where 列名 = 'xxx';
1. 创建索引之前的查找
-
在一个页中查找 假设目前表中数据较少,所有记录都可以被存在一个页中,在查找是可以根据条件分为两种情况:
-
以主键为搜索条件 可以在页目录中使用二分法快速定位到对应的槽,再遍历该槽位对应分组中的记录即可找到指定记录。
-
以其他列为搜索条件 因为在数据页中没有对非主键建立所谓的目录,所以无法通过二分法查找,只能通过最小记录依次遍历单链表中的每条记录,然后对比每条记录是不是要查找的记录,效率很低。
-
在很多页中查找 大多数情况数据是非常多的,会用很多个数据页存储,在很多数据也中查找可以分为连个步骤:
- 定位到所在的页
- 从所在的页内查找相应记录
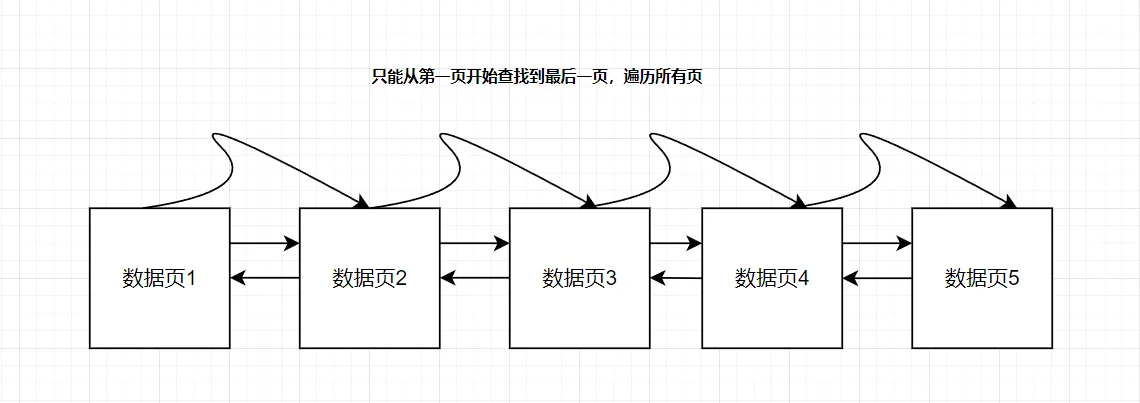
在没有索引的情况下,由于不能快速定位记录所在的页,需要从第一个页沿着双向链表,一个页一个页的向下查找,需要遍历所有页,效率超级低,此时索引应运而生。
2. 设计索引
新建一个表:
CREATE table index_demo (
ID int primary key auto_increment,
name char(1),
passwd char(1)
) ROW_FORMAT = Compact;
- COMPACT行格式
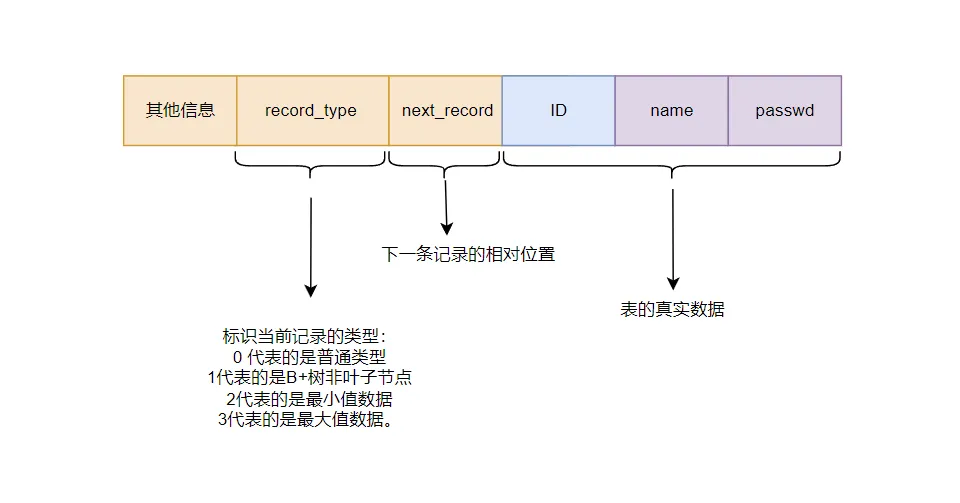
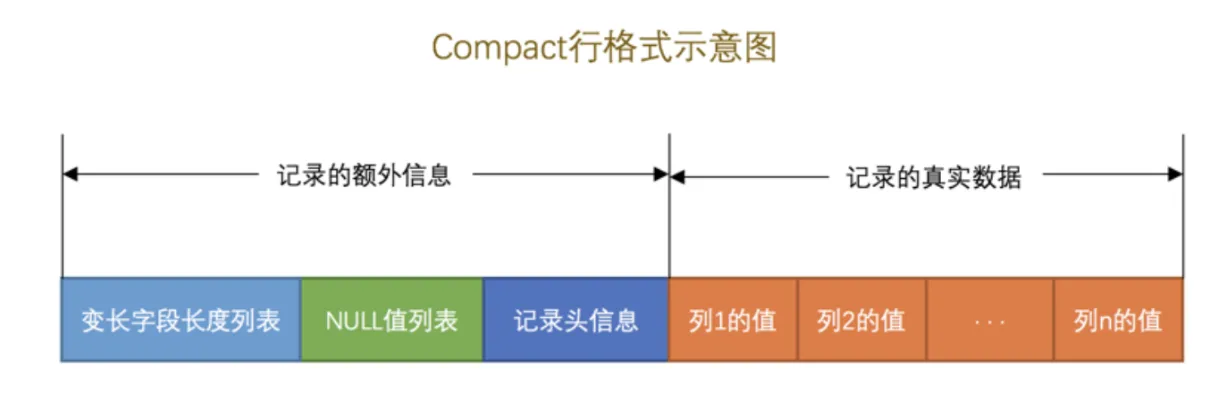 那么我们表的简易行格式为:
那么我们表的简易行格式为:
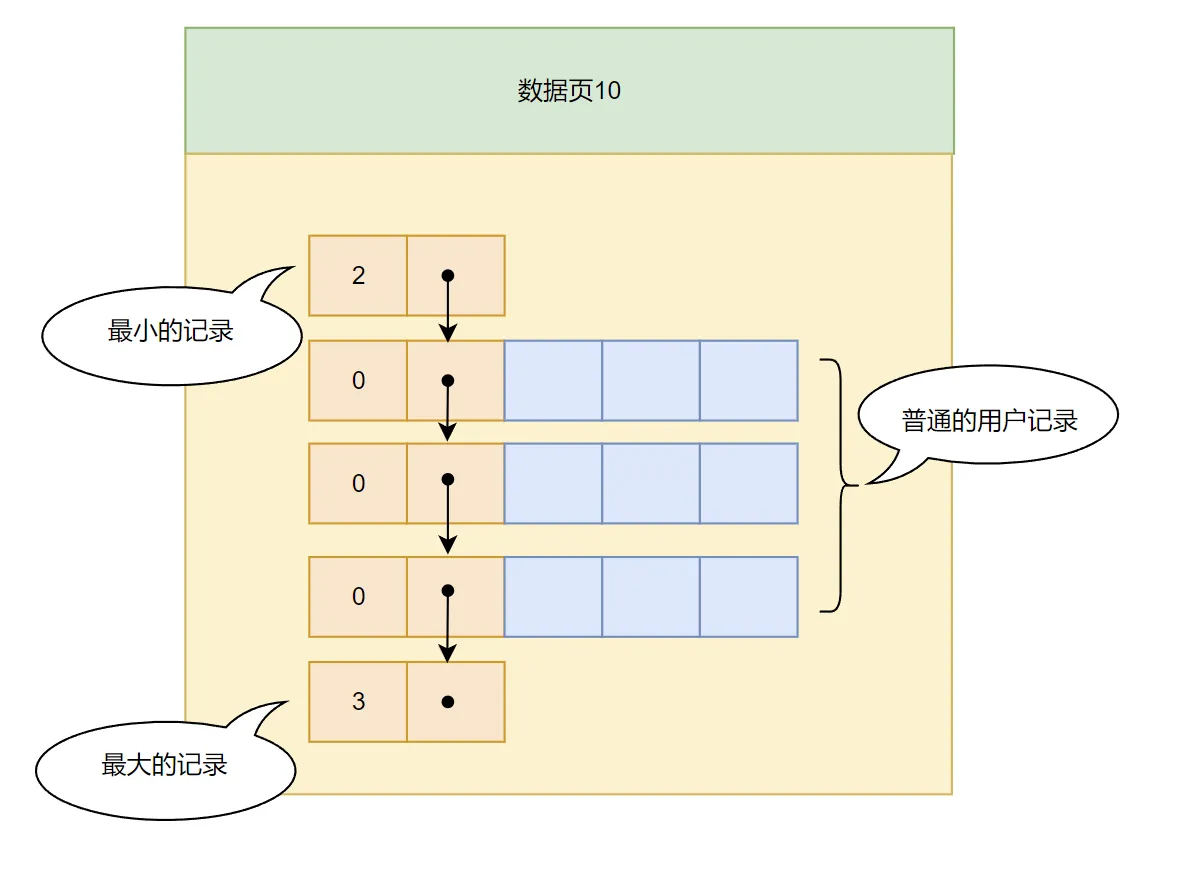
 由上可知,把一些数据放到页里面就是如下所示:
由上可知,把一些数据放到页里面就是如下所示:
2.1 一个简单的索引设计方案
为了快速定位我们所查找的数据在哪个数据页,而不必遍历所有数据页,我们可以给数据页建立一个目录项。 而建立目录则需要完成以下这些条件:
- **条件1:**下一个数据页中的用户记录的主键必须大于上一个数据页中的用户记录主键值。 假设,每个页中最多能放三条记录(实际能放很多),有了这个假设之后,我们向表中插入三条数据:
insert into index_demo values (1, 'a', '123'),(2, 'a', '123'),(3, 'a', '123');
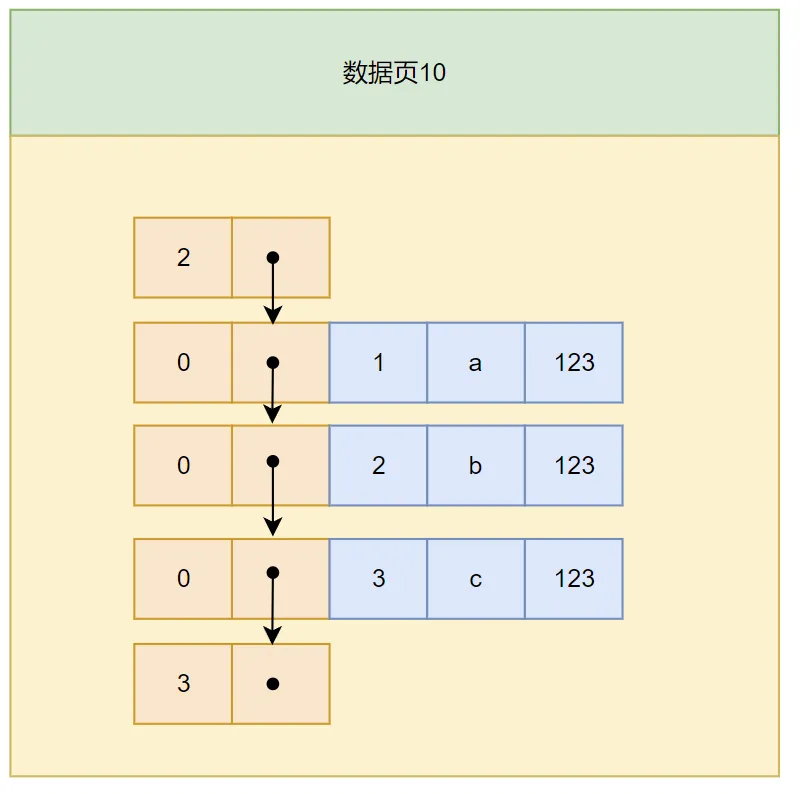
从图中可以看到,表中的三条记录都被插入到数据页10中,此时我们在插入一条数据: **注意:**后续如果插入记录的主键值如果小于已有记录,需要通过记录移动来保持主键一直是递增的。
insert into index_demo values (4, 'd', '123');
由于一个页只能存放三条记录,所以此时需要另外一个页存放此记录。
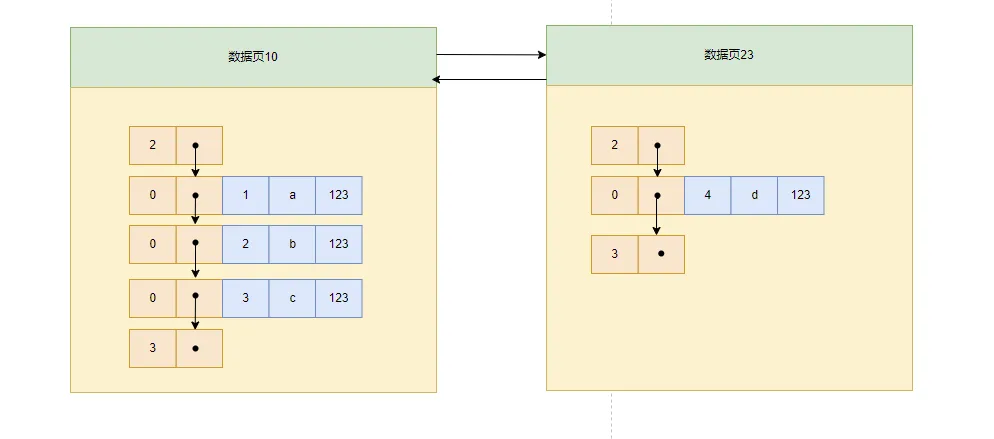
- **条件2:**给所有的页建立一个目录项。
由于数据页的编号可能是不连续的,所以在向表中插入许多条记录后,可能是这样的结果:
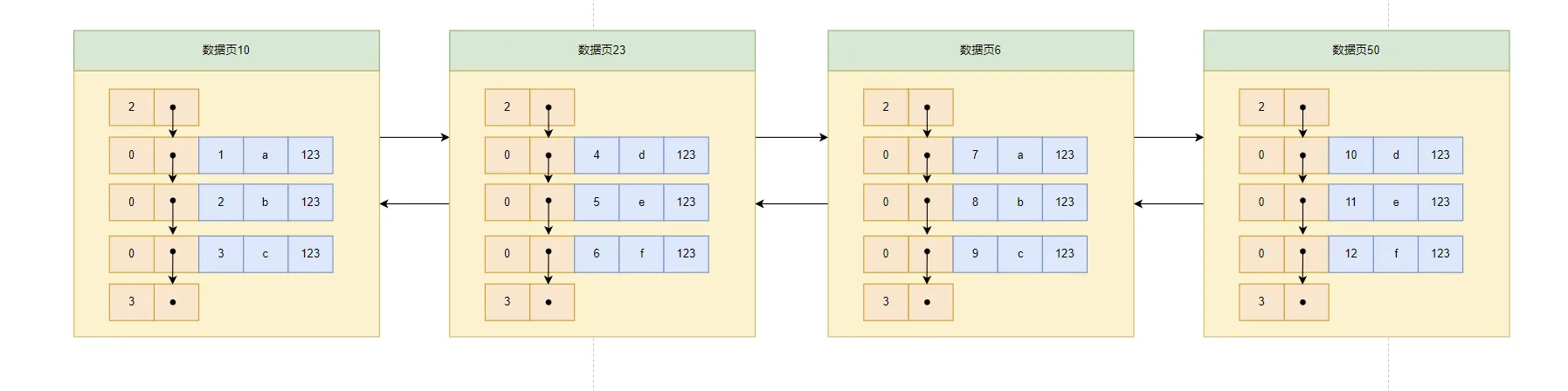
因为这些默认大小为16KB的页,在内存上地址不是连续的,所以我们为了能够快速找到我们要查找的记录在哪个页中,我们需要给这些页建一个目录。每个页对应一个一个目录项,每个目录项下包含下边两个部分: (1)页中用户记录中最小的主键值,用key表示。 (2)目录项中,每个页的编号,用page_num表示。 所以,根据以上设定,我们可以得到做好的目录图示:
所以,根据以上设定,我们可以得到做好的目录图示:
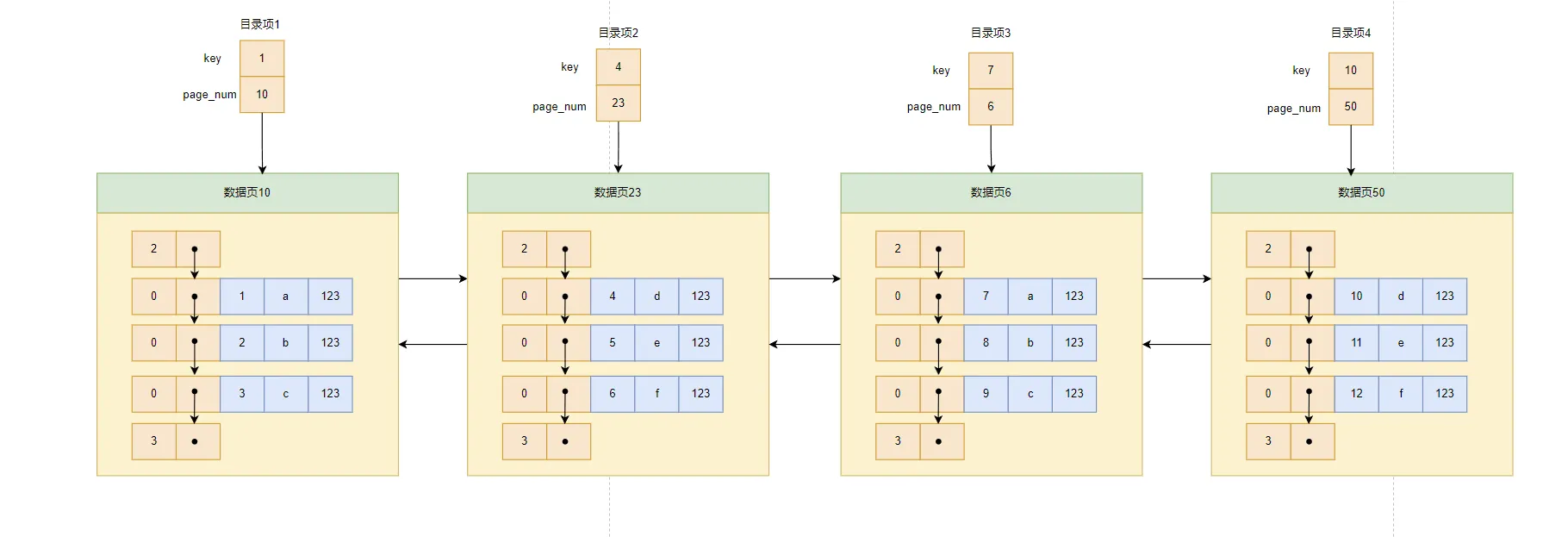 这样,比如如果我们要查找ID=9的数据:
这样,比如如果我们要查找ID=9的数据:
- 先从目录项中,根据二分法,可以快速得到,ID=9的记录在目录项3中(7<9<10),根据page_num可以得到数据页的编号是6
- 再根据前面说的在一个页中查找记录的方法去页6中快速找到所需要的记录。
但是,随着数据越来越多,会生成越来越多的数据页,也会有越来越多的目录项,由于目录项在内存空间是连续地址存储的,数据项比较多之后,对内存压力比较大,而且修改和删除数据时,也需要去维护目录项,比较消耗资源。 由于目录项中记录的内容和记录相似,原理相同,因此可以将目录项使用单向链表的方式连接在一起,达到逻辑上的连续,而不必连续内存存储,所以也可以将他们放在一个页中,为了区分,称为目录页(本质也是数据页)。
2.2 InnoDB中的索引方案
①第一次迭代:目录项记录的页(使用目录页)
根据上边的方案有点和缺点,我们进一步的设计一个目录页,用于存放目录项。
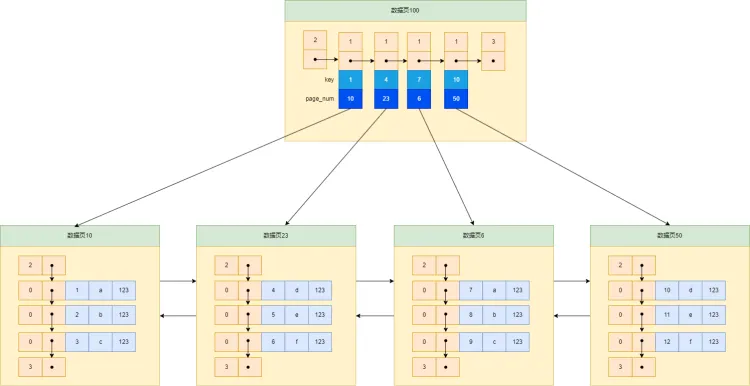 这样,比如如果我们要查找ID=9的数据:
这样,比如如果我们要查找ID=9的数据:
- 先找到目录项的页,根据在页中查找记录的方法(因为页中会为主键值生成页目录,可以用二分法),可以快定位到对应的记录,因为7<9<10,可以得到对应的页是6。
- 再根据前面说的在一个页中查找记录的方法去页6中快速找到所需要的记录。 只需要两次I/O。
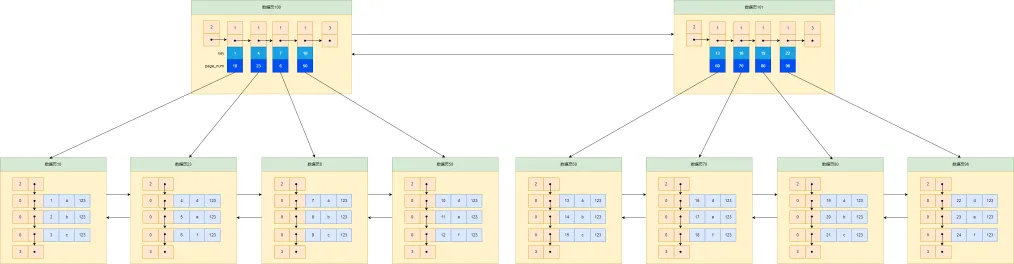
②第二次迭代:多个目录页情况
根据上述结构,当数据越来越多,目录页也会越多,如下图所示,这时候要查找记录需要先对所有目录页进行遍历,效率很低。
③第三次迭代:给目录页建立一个目录项
根据上边的情况,我们再给目录页建立一个目录项,并且使用页存储,可以得到如下图示:
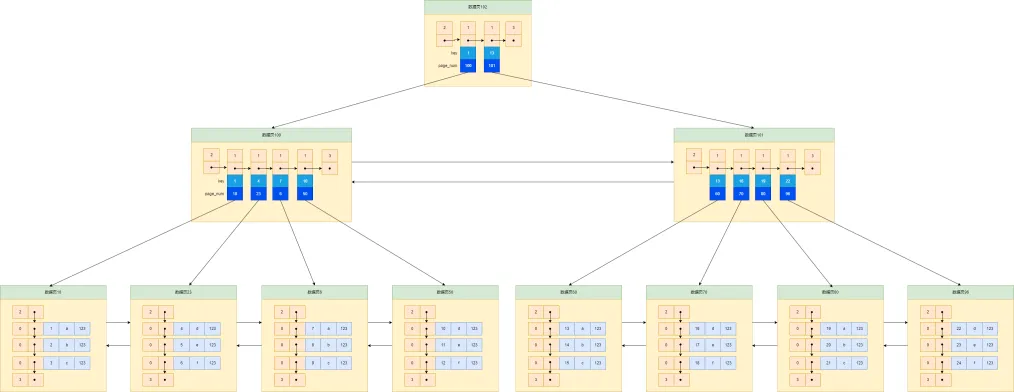 这样,如果我们要查找ID=9的数据:
这样,如果我们要查找ID=9的数据:
- 先在目录页的目录项中查找在哪个目录页,根据二分法,1<9<13,可以快速定位到页100中,在根据二分法,7<9<10,可以定位到页6中。
- 在页6中根据二分法获取对应的记录。 这样I/O的次数就相比第二次迭代减少了很多。
④第四次迭代:B+树
随着表中的记录越来越多,这个目录的层级也会增加,如果简化一下,可以用下图来表示:
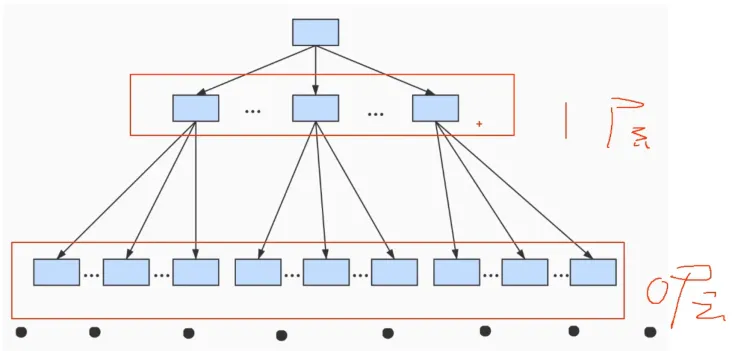
这个数据结构称为B+树。 不论是存放用户记录的数据页,还是存放目录记录的数据页,我们都把它存放到B+树这个数据结构中了,所以我们称这些数据页为节点。从途中可以看出,我们的用户记录都存在最底层的节点上,这些节点也称为叶子节点,其余用来存放目录项的节点称为非叶子节点,或者内节点,其中B+树最上边的节点也称根节点。
一个B+树的节点其实可以分为很多层,规定最下边的那层,也就是我们存放用户记录的那层为第0层,后面的层依次往上加,之前我们假设每个数据也中只能存放三条记录,但其实真是环境中一个数据页存放的记录数是可以很多的,所以在开发过程中,我们一般用到的B+树都不会超过四层。 树的层次越低,I/O次数越少。
3. InnoDB中B+树索引的注意事项
3.1 根页面完位置万年不变
我们前面探索B+树的时候,是先把存储用户记录的叶子节点先画出来的,然后画出存储叶子节点的页目录,实际上B+树是这样存储数据的。 ● 每当为摸一个标创建一个B+树索引(聚簇索引不是认为创建的,默认就有),都会为这个索引出创建一个根节点页面,最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有数据,也没有对应的目录页。 ● 随后想表中插入数据,先把用户记录存放到这个根节点页中。 ● 当根节点页中的空间用完时,继续插入数据,此时会将此页中的数据复制到一个新的页a中,然后对这个新的页a进行页分裂操作,得到一个新的页b,这是新插入的数据根据主键排序存入到页a或者页b中,而之前的根节点页面就提升为a和b的目录页。
3.2 内节点中目录页的唯一性
对于二级索引来说,目录页,也就是非叶子节点内,还要存储一个主键值,保证目录页中每一条记录都唯一。
3.3 一个页内最少存储两条记录
只存放一条记录没意义,无法形成二叉树。